

【课程介绍】


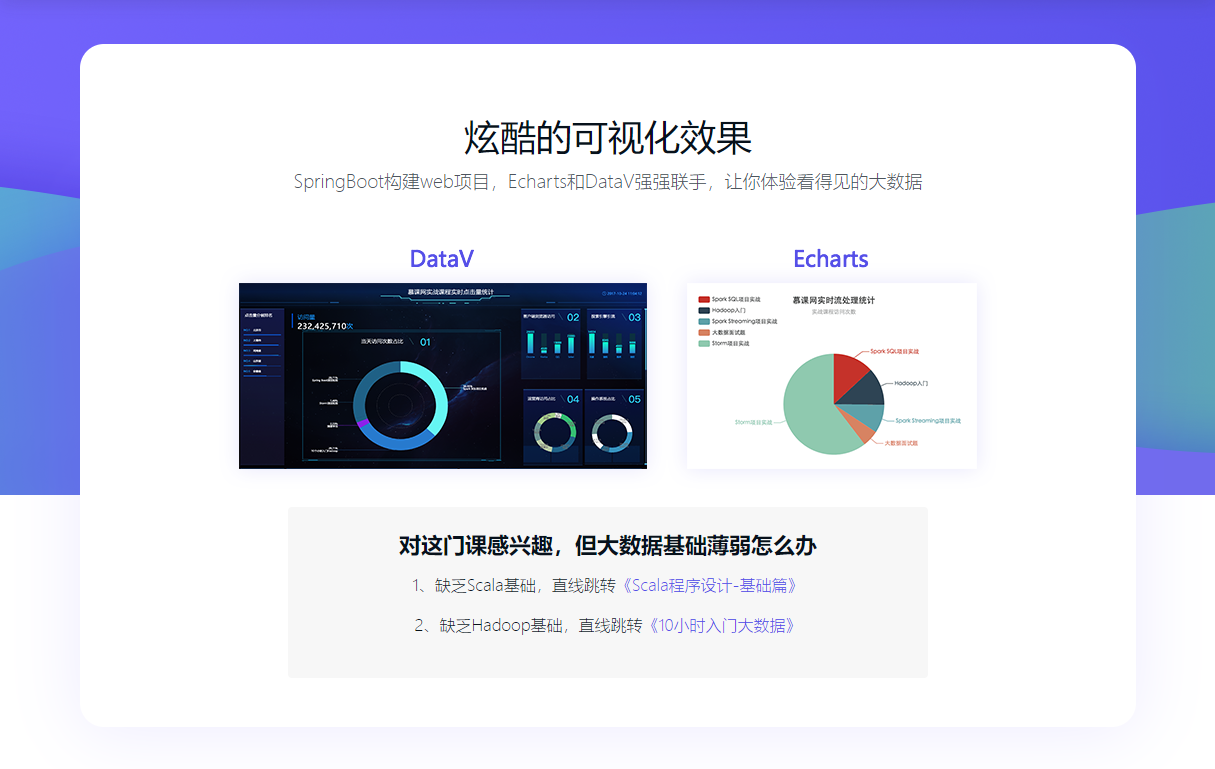

本课程从实时数据产生和流向的各个环节出发,通过集成主流的分布式日志收集框架Flume、分布式消息队列Kafka、分布式列式数据库HBase、及当前非常火爆的Spark Streaming打造实时流处理项目实战,让你掌握实时处理的整套处理流程,达到大数据中级研发工程师的水平!
【课程目录】
第1章 课程介绍
课程介绍
1-1 -导学-
1-2 -授课习惯和学习建议
1-3 -OOTB环境使用演示
1-4 -Linux环境及软件版本介绍
1-5 -Spark版本升级
第2章 初识实时流处理
本章节将从一个业务场景分析出发引出实时流处理的产生背景,对比离线处理和实时处理的区别,了解常用的实时流处理框架有哪些,实时流处理在企业级应用中各个环节的架构以及技术选型
2-1 -课程目录
2-2 -业务现状分析
2-3 -实时流处理产生背景
2-4 -实时流处理概述
2-5 -离线计算和实时计算对比
2-6 -实时流处理框架对比
2-7 -实时流处理架构及技术选型
2-8 -实时流处理在企业中的应用
第3章 分布式日志收集框架Flume
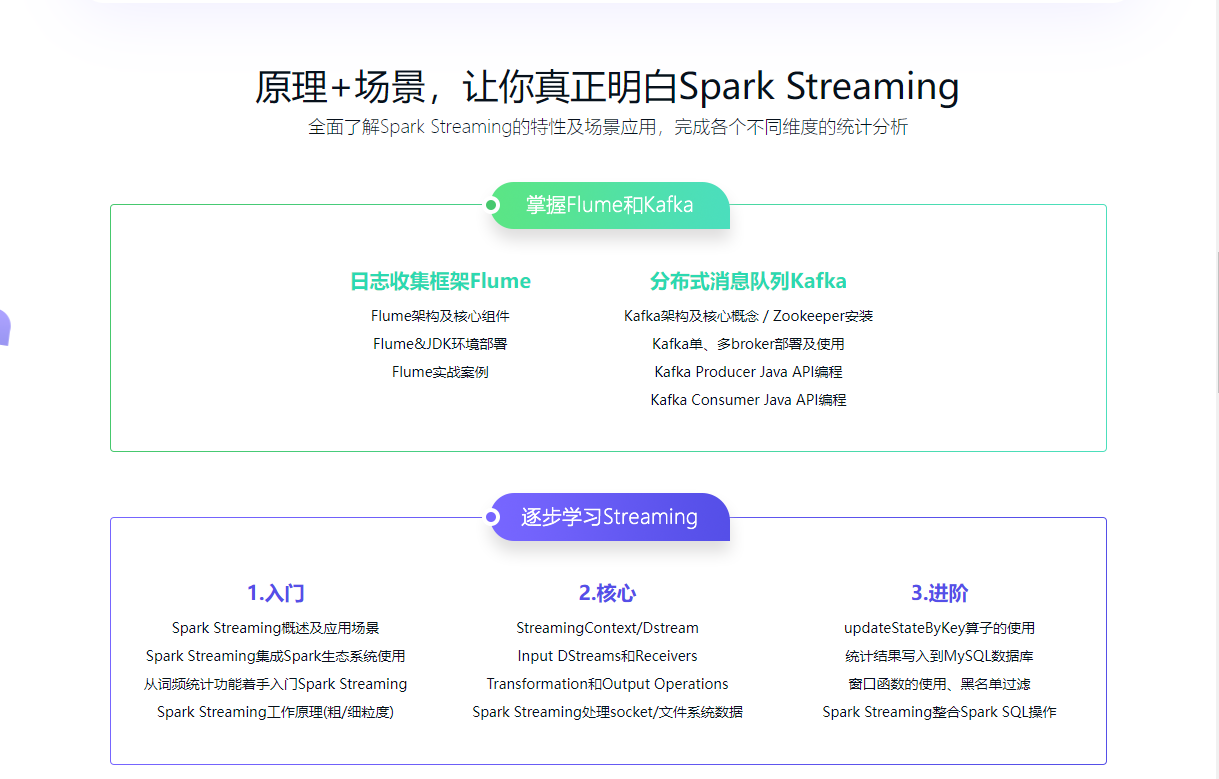
本章节将从通过一个业务场景出发引出Flume的产生背景,将讲解Flume的架构及核心组件,Flume环境部署以及Flume Agent开发实战让大家学会如何使用Flume来进行日志的采集
3-1 -课程目录
3-2 -业务现状分析
3-3 -Flume概述
3-4 -Flume架构及核心组件
3-5 -Flume&JDK环境部署
3-6 -Flume实战案例一
3-7 -Flume实战案例二
3-8 -Flume实战案例三(重点掌握)
第4章 分布式发布订阅消息系统Kafka
本章节将讲解Kafka的架构以及核心概念,Kafka环境的部署及脚本的使用,Kafka API编程,并通过Kafka容错性测试让大家体会到Kakfa的高可用性,并将Flume和Kafka整合起来开发一个功能
4-1 -课程目录
4-2 -Kafka概述
4-3 -Kafka架构及核心概念
4-4 -Kafka单节点单Broker部署之Zookeeper安装
4-5 -Kafka单节点单broker的部署及使用
4-6 -Kafka单节点多broker部署及使用
4-7 -Kafka容错性测试
4-8 -使用IDEA+Maven构建开发环境
4-9 -Kafka Producer Java API编程
4-10 -Kafka Consumer Java API编程
4-11 -Kafka实战之整合Flume和Kafka完成实时数据采集
第5章 实战环境搭建
工欲善其事必先利其器,本章将讲解Hadoop、ZooKeeper、HBase、Spark的安装,以及如何使用IDEA整合Maven/Spark/HBase/Hadoop来搭建我们的开发环境
5-1 -课程目录
5-2 -Scala安装
5-3 -Maven安装
5-4 -Hadoop环境搭建
5-5 -HBase安装
5-6 -Spark环境搭建
5-7 -开发环境搭建
第6章 Spark Streaming入门
本章节将讲解Spark Streaming是什么,了解Spark Streaming的应用场景及发展史,并从词频统计案例入手带大家了解Spark Streaming的工作原理
6-1 -课程目录
6-2 -Spark Streaming概述
6-3 -Spark Streaming应用场景
6-4 -Spark Streaming集成Spark生态系统的使用
6-5 -Spark Streaming发展史
6-6 -从词频统计功能着手入门Spark Streaming
6-7 -Spark Streaming工作原理(粗粒度)
6-8 -Spark Streaming工作原理(细粒度)
第7章 Spark Streaming核心概念与编程
本章节将讲解Spark Streaming中的核心概念、常用操作,通过Spark Streaming如何操作socket以及HDFS上的数据让大家进一步了解Spark Streaming的编程
7-1 -课程目录
7-2 -核心概念之StreamingContext
7-3 -核心概念之DStream
7-4 -核心概念之Input DStreams和Receivers
7-5 -核心概念之Transformation和Output Operations
7-6 -案例实战之Spark Streaming处理socket数据
7-7 -案例实战之Spark Streaming处理文件系统数据
第8章 Spark Streaming进阶与案例实战
本章节将讲解Spark Streaming如何处理带状态的数据,通过案例让大家知道Spark Streaming如何写数据到MySQL,Spark Streaming如何整合Spark SQL进行操作
8-1 -课程目录
8-2 -实战之updateStateByKey算子的使用
8-3 -实战之将统计结果写入到MySQL数据库中
8-4 -实战之窗口函数的使用
8-5 -实战之黑名单过滤
8-6 -实战之Spark Streaming整合Spark SQL操作
第9章 Spark Streaming整合Flume
本章节将讲解Spark Streaming整合Flume的两种方式,讲解如何在本地进行开发测试,如何在服务器上进行测试
9-1 -课程目录
9-2 -Push方式整合之概述
9-3 -Push方式整合之Flume Agent配置开发
9-4 -Push方式整合之Spark Streaming应用开发
9-5 -Push方式整合之本地环境联调
9-6 -Push方式整合之服务器环境联调
9-7 -Pull方式整合之概述
9-8 -Pull方式整合之Flume Agent配置开发
9-9 -Pull方式整合之Spark Streaming应用开发
9-10 -Pull方式整合之本地环境联调
9-11 -Pull方式整合之服务器环境联调
第10章 Spark Streaming整合Kafka
本章节将讲解Spark Streaming整合Kafka的两种方式,讲解如何在本地进行开发测试,如何在服务器上进行测试
10-1 -课程目录
10-2 -Spark Streaming整合Kafka的版本选择详解
10-3 -Receiver方式整合之概述
10-4 -Receiver方式整合之Kafka测试
10-5 -Receiver方式整合之Spark Streaming应用开发
10-6 -Receiver方式整合之本地环境联调
10-7 -Receiver方式整合之服务器环境联调及Streaming UI讲解
10-8 -Direct方式整合之概述
10-9 -Direct方式整合之Spark Streaming应用开发及本地环境测试
10-10 -Direct方式整合之服务器环境联调
第11章 Spark Streaming整合Flume&Kafka打造通用流处理基础
本章节将通过实战案例彻底打通Spark Streaming和Flume以及Kafka的综合使用,为后续项目实战打下坚实的基础
11-1 -课程目录
11-2 -处理流程画图剖析
11-3 -日志产生器开发并结合log4j完成日志的输出
11-4 -使用Flume采集Log4j产生的日志
11-5 -使用KafkaSInk将Flume收集到的数据输出到Kafka
11-6 -Spark Streaming消费Kafka的数据进行统计
11-7 -本地测试和生产环境使用的拓展
第12章 Spark Streaming项目实战
本章节将通过一个完整的项目实战让大家学会大数据实时流处理的各个环境的整合,如何根据业务需要来设计HBase的rowkey
12-1 -课程目录
12-2 -需求说明
12-3 -用户行为日志介绍
12-4 -Python日志产生器开发之产生访问url和ip信息
12-5 -Python日志产生器开发之产生referer和状态码信息
12-6 -Python日志产生器开发之产生日志访问时间
12-7 -Python日志产生器服务器测试并将日志写入到文件中
12-8 -通过定时调度工具每一分钟产生一批数据
12-9 -使用Flume实时收集日志信息
12-10 -对接实时日志数据到Kafka并输出到控制台测试
12-11 -Spark Streaming对接Kafka的数据进行消费
12-12 -使用Spark Streaming完成数据清洗操作
12-13 -功能一之需求分析及存储结果技术选型分析
12-14 -功能一之数据库访问DAO层方法定义
12-15 -功能一之HBase操作工具类开发
12-16 -功能一之数据库访问DAO层方法实现
12-17 -功能一之将Spark Streaming的处理结果写入到HBase中
12-18 -功能二之需求分析及HBase设计&HBase数据访问层开发
12-19 -功能二之功能实现及本地测试
12-20 -将项目运行在服务器环境中
第13章 可视化实战
本章节将通过两种方式来实现实时流处理结果的可视化操作,一是使用Spring Boot整合Echarts实现,二是使用更加炫酷的阿里云产品DataV来实现
13-1 -课程目录
13-2 -为什么需要可视化
13-3 -构建Spring Boot项目
13-4 -Echarts概述
13-5 -Spring Boot整合Echarts绘制静态数据柱状图
13-6 -Spring Boot整合Echarts绘制静态数据饼图
13-7 -项目目录调整
13-8 -根据天来获取HBase表中的实战课程访问次数
13-9 -实战课程访问量domain以及dao开发
13-10 -实战课程访问量Web层开发
13-11 -实战课程访问量实时查询展示功能实现及扩展
13-12 -Spring Boot项目部署到服务器上运行
13-13 -阿里云DataV数据可视化介绍
13-14 -DataV展示统计结果功能实现
第14章 Java拓展
本章节作为扩展内容,将带领大家使用Java来开始Spark应用程序,使得大家对于使用Scala以及Java来开发Spark应用程序都有很好的认识
14-1 -课程目录
14-2 -使用Java开发Spark应用程序
14-3 -使用Java开发Spark Streaming应用程序
第15章 补充内容
Spark Streaming整合Kafka的offset管理以及消费语义
15-1 -课程目录
15-2 -流处理语义详解
15-3 -Kafka整合SparkStreaming的offsets管理宏观介绍
15-4 -环境准备
15-5 -offset管理演示一
15-6 -offset管理演示二
15-7 -offset管理演示三
15-8 -计算结果一致性
15-9 -补充内容总结
第16章 (讨论群内直播内容分享)Spark流处理面试三两事
本次分享将从Kafka ack机制、Kafka数据文件存储、不同消费策略从源码的角度进行剖析,帮助同学们掌握在Spark流处理项目中的面试常考点。
16-1 SparkStreaming整合Kafka面试常考点梳理
16-2 面试常考点之ack剖析
16-3 面试常考点之Kafka数据存储剖析
16-4 面试常考点之Kafka数据消费策略概述
16-5 面试常考点之基于Range消费策略详解
16-6 面试常考点之基于Range消费策略源码解析
16-7 面试常考点之基于RoundRobin消费策略分析